Thoughts on Stable Diffusion 2
Models-turtles, retraining hurdles, and step towards ClosedAI.
Because most articles and videos covering Stable Diffusion 2 simply regurgitated the contents of the release, I decided to fill the gap and write about what it means.
As I’ve only been around generative AI for a few years, take this with a grain of salt and consider this post as mere kindling for the fire of your own thinking.
Models-turtles: It is gonna be models all the way down
If you’ve played around with GPT-3, you know that the most interesting/well-performing results never come from any single model — they come from a stack/system of models that work together in perfect sync. For instance, all decent chatbots nowadays have one model for generating text, another one for classifying the generations by relevance, yet another one for sentiment analysis, and then perhaps one more for something more exotic, like role-play. My friend Max’s Anima is a good example.
The same ‘model stacking’ practice is happening with image generation now and is pushed further with the release of SD2 models. For instance, a default text2img SD2 model can only generate images of 768x768 resolution, but if you combine it with a super-resolution SD2 upscaler, you can suddenly get stupendous 3072x3072.
Since models seem to work best when they’re specialized, I expect that all SOTA AI apps in the future will be using tons of models put together in weird ways, as we do with npm packages now when building software. In fact, this is already happening: Pieter Levels, the maker of popular AvatarAI and InteriorAI services (that made stupendous $100k+ in ten days after launch), is using not one but a dozen models put together like Lego blocks. Examples include: text2img, upscalers, face restoration, DALL-E for outpainting, and many more.
Max Rovensky went even further: he took a picture generated by Pieter’s AvatarAI (already a stack of models!), upscaled it even further, and then outpainted with DALL-E for a vertical aspect ratio for social media. The result is incredible.

Furthermore, the newly released SD2 depth2img model itself is actually not one model but a combination of many! It uses an SD2 base text2img in combo with a famous MiDaS for depth inference to make images using both text and depth information. Ditto for the text2img model itself: to generate 512x512 or 768x768 images at a reasonable speed, it first creates a picture of a much smaller resolution and then uses a built-in upscaler to enhance the image’s quality. Ditto for GPT-3 and many other models.
The best way to think of these stacks/integrations is Lego. The more pieces you got, and the more diverse they are, the cooler the things you can build. Same with models: the more models we have, and the more specialized they are, the broader the spectrum of possibilities. It looks like, in the end, it’s going to be models standing on models, all the way down, amounting to Bugatti-like complexities and possibilities.

P.s. Interestingly, Stability AI’s strategy is similar to model stacking: to get millions of people involved and hope that such a vast number will yield interesting system effects. Here’s how they put it in the release: “...when millions of people get their hands on these models, they collectively create some truly amazing things. This is the power of open source: tapping the vast potential of millions of talented people who might not have the resources to train a state-of-the-art model, but who have the ability to do something incredible with one.” It surely worked.
Retraining hurdles: How many times are we going to start from scratch?
If you’ve been around Stable Diffusion subreddit and Discord for the past two days, you may have noticed legions of unhappy users. The reason they’re unhappy is quite simple: with the release of SD2, their knowledge of how to prompt the model to get top-notch generations is obsolete. Many of the prompts that yield exceptional results in SD 1.4 or 1.5 generate crap in SD2.
Why? Two reasons. First, Stability AI replaced OpenAI’s CLIP encoder with the one built by LAION. As Emad put it, this means that “...overall model ‘knows’ different things to the previous Stable Diffusion v1.” Second, unlike every other version before it, SD2 was trained from scratch. Per known physics of the universe, this means that the neural network’s weights will be different, want it or not.
What I’m interested in is a) how many more re-trainings of SD and other foundation models there is going to be; and b) is there anything to be done to make these re-trainings less disastrous to our knowledge of how to use the models. As for a), my intuition and knowledge of tech regulations history tell me this is not the last one. (More on this in the next section.) As for b), one idea is to build “bridges:” train a model like GPT-3 to transform the prompts that work well in SD 1.5 into prompts that will work well in SD2. Given enough data, such a transformer shouldn’t be terribly hard to build. If you make it, let me know.
Step towards ClosedAI: Has Stability AI just taken the first one?
The lost art of prompting is not the only thing SD users are angry about. It can and will be restored, for there’s no alternative there. What can’t be restored, however, is people’s trust in the mission, and it seems that with the newly introduced NSFW filter, Stability AI is at risk of losing it.
Before the Stability guys showed up, we lived in a world of OpenAI, which is ironic since there was little “open” about it. The thing that made Stability AI work, in my opinion, was not better models; it was their unfaltering commitment to radical openness, reflected in the slogan: “AI by the people, for the people.” Now, with the NSFW filter, they’ve broken that commitment. I understand why they did it, though: with great power comes great responsibility (and people in suits knocking). As Emad commented here, you “can’t have kids & nswf in an open model.” With the rapid rise of Stable Diffusion’s popularity, they either had to a) remove NSFW, annoy some users, but don’t get legislated by the government and conquer schools/etc.; or b) leave NSFW, get legislated, and hinder growth.
But, reading through the angry Twitter and Reddit replies of their fans and the announcement of Unstable Diffusion, I can’t help but wonder if Stability AI is not undermining the very thing that made it work, mutating into ClosedAI, and vacating the site for the next “truly open” rival to try and build “AI by the people, for the people,” fail, and submit to the wants of the public again. We’ll see.
Some good commentary on the issue:
- A compilation of Emad’s talk on SD2 on Nov 24th;
- A Reddit thread on the removal of artists due to the dataset switch;
- A proposal to start a new, “truly open-source,” Stability AI;
- A Reddit post arguing that Stability has given up its mission;
Random thought: Why did Stable Diffusion’s open-source strategy work on such a grand scale?
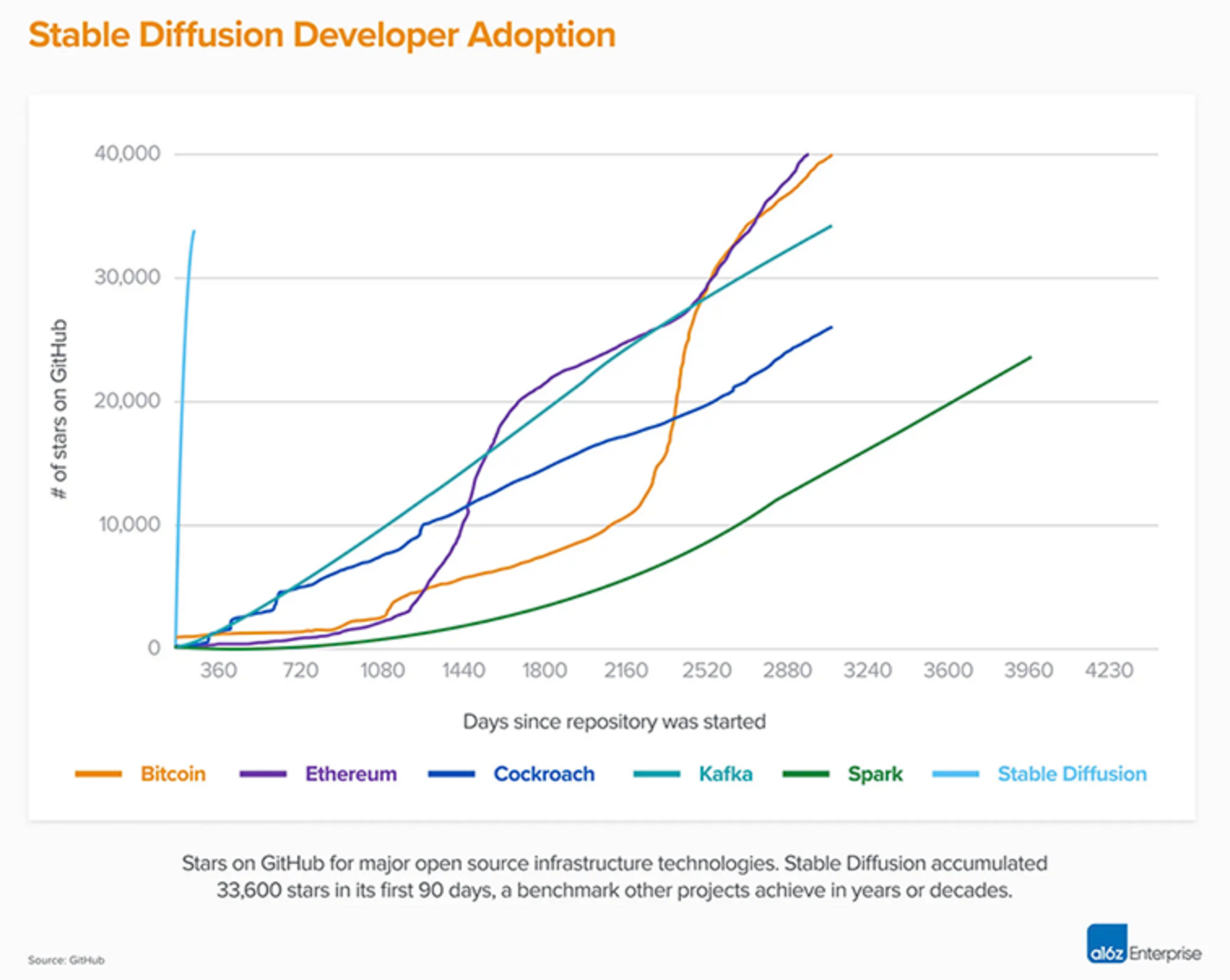
It was surprising for me how quickly Stable Diffusion and the whole generative AI space evolved, given that it was open source. If you had told me six months ago that open-source collectives could accomplish such a feat, I’d have never believed you.
Why did it work so well? Two reasons, I think: 1) the product of this software is visual; and 2) one can make their own images with it. The former makes it appealing to virtually everyone, and the latter taps into everybody’s inner artist and contributes to their status because they can show their amazing or hilarious creations to others. If Stable Diffusion made a model in any other medium, say, audio, or if its software didn’t allow tinkering with generations, personalizing them, I don’t think it would have worked so well.